


Links
Screencast
Ich habe alle hier beschriebenen Schritte inkl. Kommentaren im Screen-Cast nachvollzogen. Aufgrund der Menge an Schritten ist es manchmal vielleicht etwas schwieriger, meinen Ausführungen im Text zu folgen. Seht Euch einfach das Video an, wenn Ihr irgendwo hängt!
Vorbemerkungen
Das Thema ist beileibe kein Neues. Die meisten Business-Anwendungen benutzen im Backend eine relationale Datenbank. Sobald es aber dazu kommt, dass man Unit-Tests für die entsprechenden Teile der Anwendung entwerden soll, stellen sich diverse Fragen:
- Woher soll ich beim Start eines Tests wissen, welche Einträge in der Datenbank vorhanden sind?
- Wie verhindere ich, dass einzelne Tests und Benutzer sich in die Quere kommen?
- Wie soll ich die Bereitstellung der Datenbank für den Test bewerkstelligen.
- Läuft das Ganze auch im Build-Server?
Wahrscheinlich könnte man noch mehr Fragezeichen aufwerfen, aber das ist im Prinzip der Ausgangspunkt vor dem ich stand.
Idee
Mein Plan war nun, einen Weg zu finden, wie ich anstellen kann, dass jeder Unit-Test-Lauf - egal von welcher Maschine aus - seine eigene Datenbank mit vorgefüllten Daten bekommt, benutzt und dann wieder löscht.
Um es gleich vorweg zu nehmen: Ich habe es geschafft, aber nur für Microsoft SQL-Datenbanken. Der Grund ist der, dass ein wesentlicher Baustein meiner Lösung die Microsoft SQL Server Data Tools (SSDT) sind und die gibt es nun einmal nur für die MS-Datenbank.
SSDT-Projekt anlegen
Um die Idee umzusetzen, brauchen wir zunächst unsere Datenbank-Definition in unserem Projekt. Ich benutze schon seit Jahren SSDT. Da ich noch keinen eigenen Artikel für SSDT gemacht habe, gehe ich hier etwas detaillierter auf die einzelnen Schritte ein.
SSDT ist ein Feature, dass man installieren/einschalten muss. Für Visual Studio 2015 und früher müsst Ihr es als einzelnes Paket bei Microsoft herunterladen. Ab Visual Studio 2017 ist es Teil der Optionen im Visual Studio Installer:
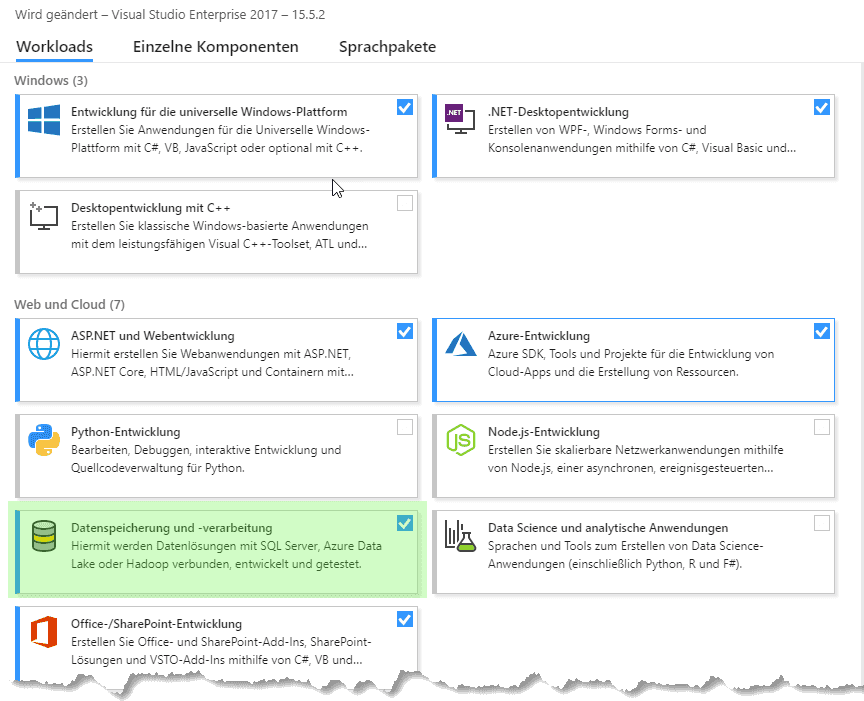
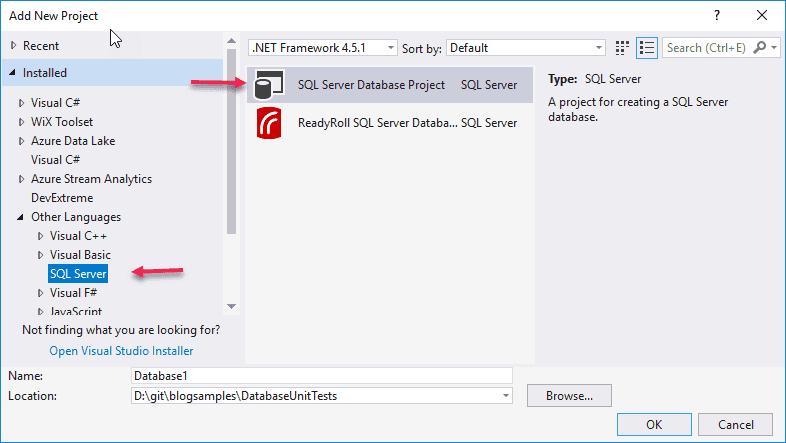
Ob alles funktioniert hat kann man testen, indem man im Visual Studio in das “New Project” fenster wechselt und prüft, ob der folgende Eintrag unter “Add New Project” vorhanden ist:
Zunächst sollte man einen Blick in die Projekt-Eigenschaften werfen. Nach einem Rechtsklick auf das Projekt im Solution Explorer und dann Auswahl von Eigenschaften öffnet sich ein etwas anderer Eigenschaften-Dialog, als man dies gewohnt ist. Die wichtigste Einstellung hier ist die “Target Platform”. Hier sollte man Einstellen, was auch immer man gerade an Datenbank im Einsatz hat. Unterstützt werden alle aktuellen OnPremise- und Azure-Versionen. Für mein Sample habe ich “SQL Server 2012” gewählt, weil ich der Einfachheit mit der LocalDb des Visual Studio arbeiten werde.
Nachdem das Projekt angelegt und eingerichtet ist, ist der einfachst mögliche Weg, von einer bestehenden Datenbank aus loszulegen.
Wer sich das Anlegen zum Ausprobieren sparen möchte, kann auch gleich das Sample-Projekt nutzen!
Zum initialen Befüllen eignet sich der sog. Schema Compare. Ein Rechtsklick auf das SSDT-Projekt im Solution Explorer und dann “Schema Compare…” öffnet das entsprechende Fenster:

Ich habe die wichtigsten Elemente markiert. Zunächst ein paar Worte zu diesem Dialog. Der Sinn ist, dass SSDT das Schema des links ausgewählten Elementes untersucht und dann mit der rechten Seite abgleicht. Es arbeitet also sehr ähnlich zu einem File-Diff nur eben mit den Schema-Informationen des SQL Server.
Wir sollten also den Doppel-Pfeil-Button anklicken, weil das Ziel unserer Operation das aktuelle SSDT-Projekt sein soll. Das Projekt wird nun rechts angezeigt.
Links ist nun nichts mehr enthalten. Also klicken wir auf die Combo-Box und wählen “Select Source…“. Es öffnet sich ein Datenbank-Auswahl-Dialog:
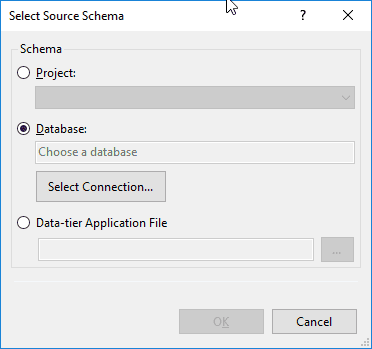
Lässt man dort die Einstellung auf “Database” und klickt dann auf “Select Connection…” erscheint (unter VS 2017) ein Browser für Datenbanken. Hier klickt man oben auf das Tab “Browse”. Da ich mir vorher eine “UnitTestSample”-Datenbank auf meiner LocalDb angelegt habe, sehen die Einstellungen für mich wie folgt aus:
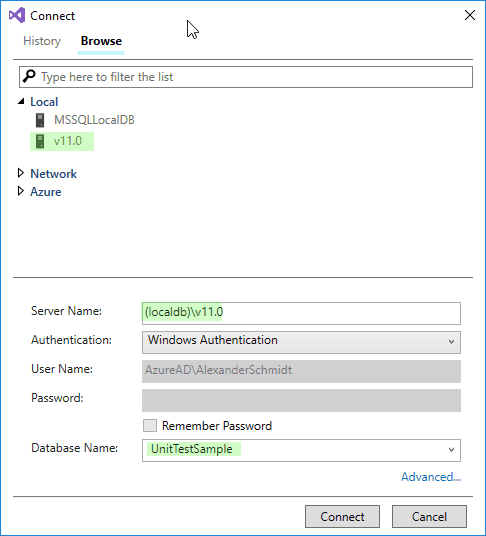
Nach einem Klick auf “Connect” und dann “OK” im Dialog aus Abb. 4 wird die Datenbank in der linken Combo-Box des Schema Compare gezeigt. Jetzt sorgt ein Klick auf “Compare” für den Abgleich. Das Ergebnis sieht beim ersten Abgleich ungefähr so aus:
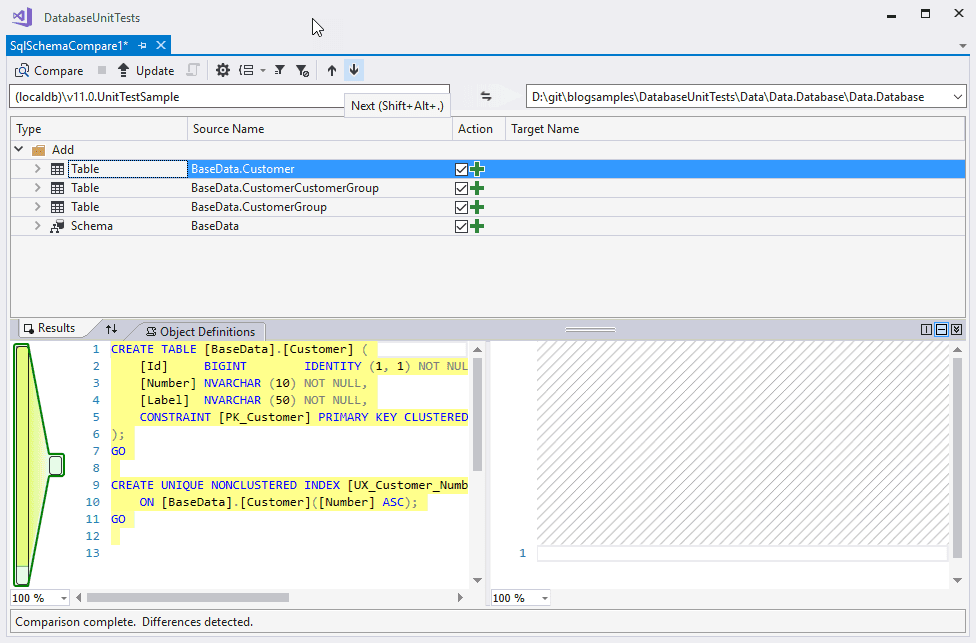
Ein Klick auf “Update” sorgt dann dafür, dass das Datenbank-Schema in unser SSDT-Projekt übernommen wird. Man kann danach das Compare-File abspeichern und dem Projekt hinzufügen, damit man später einfach Updates durchführen kann. Die Projektstruktur sieht in meinem Beispiel-Projekt zum Schluss so aus:
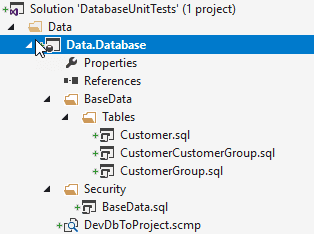
Das Script hat mein Schema “BaseData” in den Ordner “Security” gepackt und für jede Tabelle des Schemas eine Datei unter “Tables” erstellt. Alle von SSDT erstellten Elemente sind ganz einfach nur DDL-SQL-Scripts.
Ab diesem Moment kann man alle zukünftigen Änderungen an der Struktur innerhalb des SSDT-Projektes vornehmen und dann über das Compare sauber in Richtung DEV-Datenbank senden.
Wir kommen bald zum SSDT-Projekt zurück. Zunächst aber erstellen wir uns ein Entity Model.
Entity Model erstellen
Für den Datenbank-Zugriff werde ich Entity Framework 6.2.0 Database First verwenden. In einem neuen Projekt “Data.Core” erstelle ich mir meine Model gegen die gleiche LocalDb-Datenbank aus dem ersten Schritt. Das Ergebnis im EF-Designer sollte so aussehen:
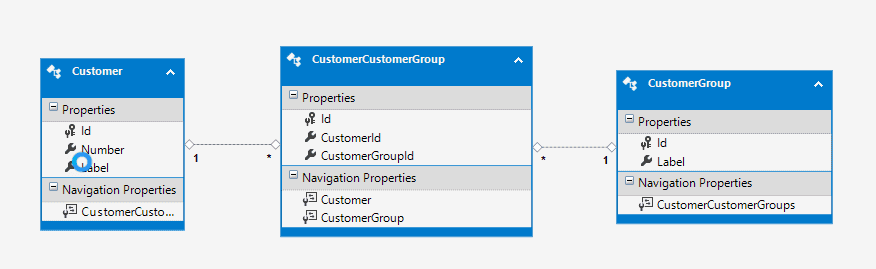
Ab jetzt kann ich also auf die Datenbank zugreifen, die zugegebener Maßen aber noch komplett leer ist. Trotzdem kann man ja schon mal testen.
Ein erster Unit Test
Ich erstelle mir ein neues Unit-Test-Projekt. Ich füge eine Unit-Test-Klasse für Customer hinzu und implementiere sie:
/// <summary>
/// Provides unit tests for customers.
/// </summary>
[TestClass]
public class CustomerTests
{
#region methods
/// <summary>
/// Checks if the current amount of customers in database matches the expected one.
/// </summary>
[TestMethod]
public async Task CheckCustomerCount()
{
// arrange
const int ExpectedCount = 0;
var realCount = -1;
// act
using (var ctx = new UnitTestSampleEntities())
{
realCount = await ctx.Customers.CountAsync();
}
// assert
Assert.AreEqual(ExpectedCount, realCount);
}
#endregion
}Damit das ganze wirklich funktioniert, muss das Unit-Test-Projekt das Entity Framework NuGet-Package bekommen und in der App.config muss der Eintrag für den ConnectionString rein.
Da ich derzeit direkt gegen die leere DEV-Datenbank teste, sollte Listing 1 erfolgreich durch die Tests laufen.
Soweit so schlecht
Zeit für ein kurzes Zwischenergebnis. Der Test läuft gegen eine Datenbank. Das ist ok, aber derzeit völlig sinnlos. Die Datenbank ist hart konfiguriert und entspricht aktuell unserer DEV-Datenbank. Füge ich hier eine Zeile ein, weil ich irgend etwas testen möchte, schlägt natürlich mein Test fehl. Ändere ich etwas an der Struktur, was ich aber den Tests noch nicht mitgeben möchte, können die Tests ebenfalls unbeabichtigt fehlschlagen. So geht es also nicht!
Database Publish
Nach all diesem Vorgeplänkel geht es nun ans Eingemachte. Den Schema Compare des SSDT-Projektes haben wir ja nun verstanden. Er synchronisiert einfach nur Datenbank-Strukturen, kümmert sich aber nicht um Daten.
Um anhand des nun bekannten Schemas ein komplette Datenbank aus dem Nichts entstehen zu lassen gibt es aber noch eine andere Option - das Database Publishing.
Klickt man rechts auf das SSDT-Projekt im Solution Explorer erscheint relativ weit oben der Menu-Eintrag “Publish”. Er öffnet den folgenden Dialog:
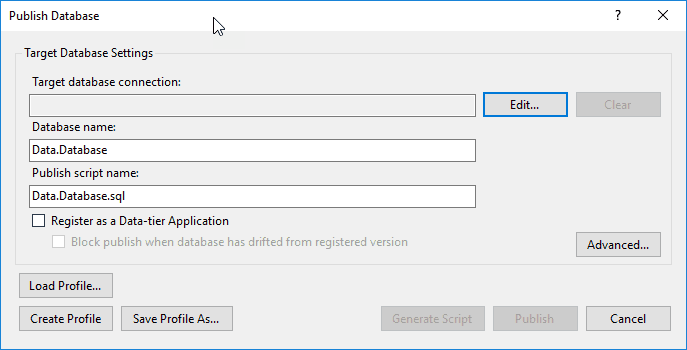
Ein Publish funktioniert hier ähnlich wie man das von Webseiten her kennt. In der Standard-Ausprägung erzeugt SSDT eine große SQL-Datei mit zunächst allen DDL-Befehlen und führt diese Datei auf einer SQL-Connection aus. Der Clou hier ist zunächst, dass ich den Datenbank-Namen ändern kann. Mit anderen Worten kann ich mein aktuelles Schema im Projekt in einem Schritt als leere Datenbank auf einen Server meiner Wahl verteilen.
Der Einfachheit halber nehme ich für das Projekt ebenfall meinen LocalDb-Server. An dieser Stelle würde man aber wahrscheinlich eher das Test-System nutzen. In unserem Fall ist das dann meist eine SQL Azure. Ich stelle den Dialog also für das Beispiel so ein:
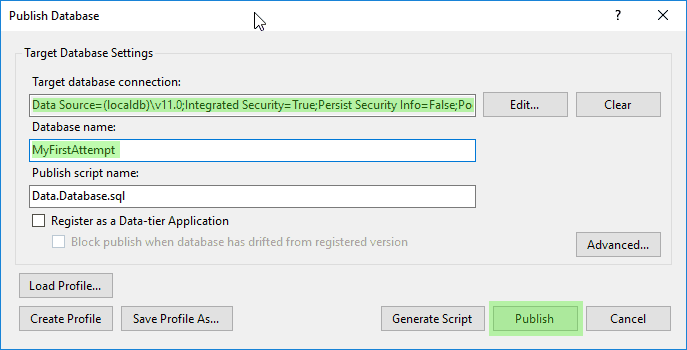
Klicke ich dann auf “Publish” wird nach kurzer Wartezeit eine komplett frische Datenbank auf meiner LocalDb erzeugt:
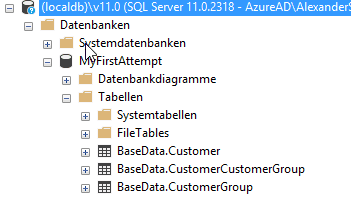
Das Problem ist jetzt eigentlich nur, dass keine Daten in dieser Datenbank vorhanden sind. Darum kümmern wir uns jetzt.
Datenbank-Seeding
Zunächst füge ich dem SSDT-Projekt über “Add -> New Item” ein sog. Post Deployment Script hinzu:

Dabei handelt es sich um ein SQL-Script, dass am Ende des Publish-Prozesses angehängt wird. Ein PostDeployment-Script kann man im Nachgang daran erkennen, dass man die Datei im Solution Explorer anklickt, dann F4 drückt, um die Eigenschaften der Datei zu sehen und folgendes überprüft:

Es gibt also eine BuildAction PostDeployment. Das wars auch schon und SSDT weiß, was zu tun ist.
Weil ich wahrscheinlich nicht unbedingt immer eine gefüllte Datenbank publishen möchte, werde ich mir eine Art Konfigurations-Wert in mein SSDT-Projekt einfügen. Bei Datenbankprojekten heißt so etwas SQLCMD-Variable. “SQLCMD” ist eigentlich ein eigenes Utility aus dem SQL Server Umfeld und erlaubt z.B. Zugriff auf Meta-Daten außerhalb der Datenbank.
Die neue Variable wird in den SSDT-Projekt-Eigenschaften im Tab SQLCMD Variables wie folgt definiert:
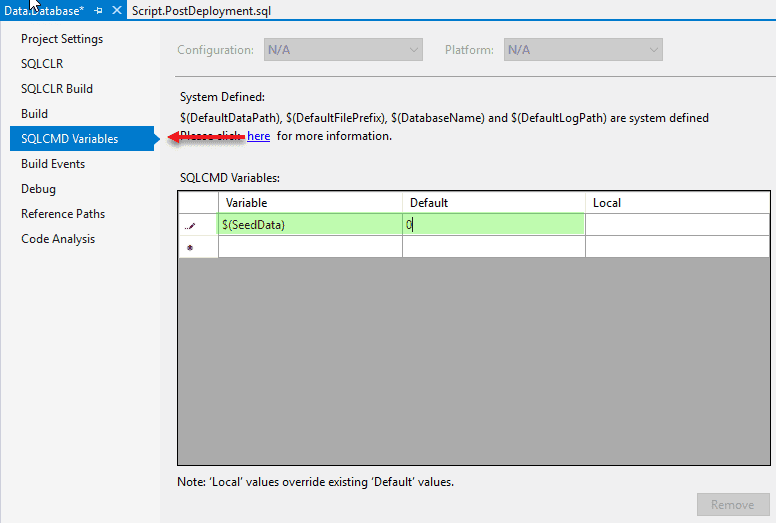
Zurück im PostDeployment-Script können wir diese Variable dann verwenden:
IF ($(SeedData) = 1)
BEGIN
END
GOWer sich hier wundert, warum Visual Studio Fehlermeldungen ausspuckt, der sein darauf hingewiesen, dass der VS-Editor nicht versteht, dass das hier ein SQLCMD-Script sein soll. Das kann man ihm aber mitteilen. Es gibt einen Button in der Toolbar des SQL-Editors:

Er funktioniert als Schalter. Klickt man ihn an, verschwinden die Fehler-Hinweise sofort.
Wie dem auch sei. Ich brauche nun etwas, was ich innerhalb des IF-Blocks tun kann. Dieses Etwas werden SQL-Scripte (ohne “CMD”) sein, die INSERT-Befehle absetzen werden. Ich sammle diese Scripte gern in einem Ordner “DeployScripts” innerhalb des SSDT-Projektes:
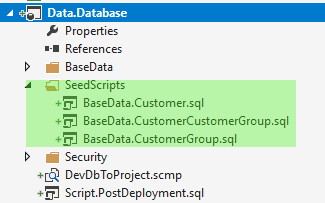
Hier der Inhalt der einzelnen Dateien:
SET IDENTITY_INSERT [BaseData].[CustomerGroup] ON
INSERT INTO [BaseData].[CustomerGroup] (Id, Label) VALUES
(1, N'Normale Kunden'),
(2, N'Gute Kunden'),
(3, N'Beste Kunden');
SET IDENTITY_INSERT [BaseData].[CustomerGroup] OFFund
SET IDENTITY_INSERT [BaseData].[Customer] ON
INSERT INTO [BaseData].[Customer] (Id, Number, Label) VALUES
(1, N'K001', N'Müller GmbH'),
(2, N'K002', N'Schulze AG'),
(3, N'K003', N'Mustermann GbR');
SET IDENTITY_INSERT [BaseData].[Customer] OFFund
SET IDENTITY_INSERT [BaseData].[CustomerCustomerGroup] ON
INSERT INTO [BaseData].[CustomerCustomerGroup] (Id, CustomerId, CustomerGroupId) VALUES
(1, 1, 2),
(2, 1, 1),
(3, 2, 3),
(4, 3, 1);
SET IDENTITY_INSERT [BaseData].[CustomerCustomerGroup] OFFDie erste und letzte Zeile jedes Scriptes schaltet ein und wieder aus, dass ich innerhalb der INSERT-Kommandos den Wert der AutoIncrement-Spalten Id setzen darf.
Jetzt muss ich diese Scripte in meinem PostDeployment noch aufrufen:
IF ($(SeedData) = 1)
BEGIN
:r .\SeedScripts\BaseData.CustomerGroup.sql
:r .\SeedScripts\BaseData.Customer.sql
:r .\SeedScripts\BaseData.CustomerCustomerGroup.sql
END
GOHier ist jetzt die Reihenfolge der Aufrufe sehr wichig. In unserem Beispiel muss BaseData.CustomerCustomerGroup.sql ganz am Ende aufgerufen werden, da sonst die Foreign-Key-Constraints zu fehlern führen würden.
Wenn ich nun das Publishing erneut aufrufe, dann sieht der Dialog leicht anders aus:

Der Dialog findet die in den Projekteinstellungen vermerkte SQLCMD-Variable SeedData und erlaubt es mir, für diesen Publish-Vorgang einen Wert für diese festzulegen. Ich setze ihn hier auf “1”.
Wichtig ist auch, den “Advanced…”-Button anzuklicken. Es erscheint dieser Dialog:
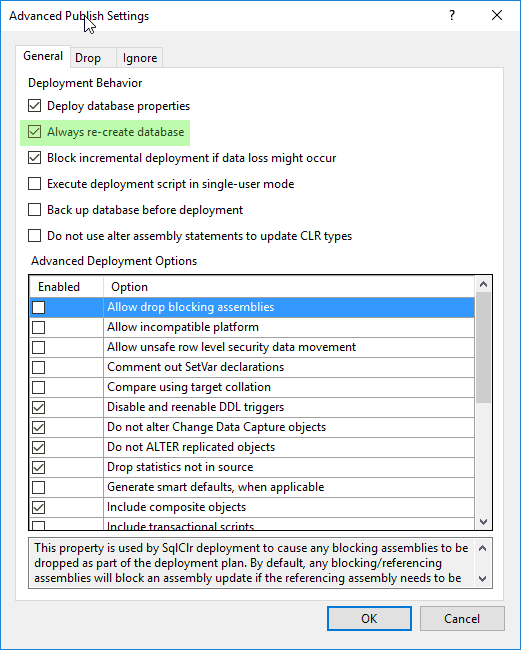
Hier hake ich “Always re-create database” an. Die Option ist normalerweise relativ gefährlich, in unserem Fall aber genau, was wir brauchen. Sie besagt einfach nur, dass beim Publish eine evtl. bereits vorhandene Datenbank “MyFirstAttempt” vorher gelöscht wird.
Zurück im Publish-Dialog klicke ich dieses Mal auf “Save Profile As…” und gebe dem Profil den Namen “TestSystemWithSeeding.pubxml”. Die Datei wird dem SSDT-Projekt hinzugefügt, was später noch wichtig wird.
Führe ich nun das Publish aus und sehe mir die Datenbank danach z.B. im SQL Management Studio an, sollten die Tabellen Daten enthalten:
Unit-Tests anpassen
Nachdem ich nun die Datenbank auf dem “Testsystem” einfach so inkl. Daten erzeugen kann, möchte ich meinen Unit-Test anpassen. In meinem Beispiel muss ich erst einmal nur die App.config öffnen und im EF-Connection-String den Wert für initial catalog finden und auf MyFirstAttempt setzen. Danach sollte der Unit-Test sofort fehlschlagen:
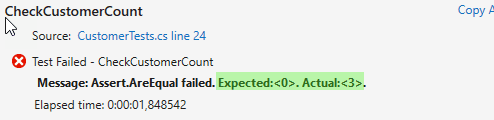
Also bekommt er als ExpectedCount jetzt die “3” zugewiesen und sollte wieder laufen.
Kommandozeile für publish
Wie aber hilft uns das Ganze nun für die notwendige Automatik? Aktuelle haben wir die Situation nur ein klein wenig verbessert, weil wir die Datenbank geseedet verteilen können.
Hier kommt uns nun der Umstand zu Hilfe, dass man SSDT-Publishings auch per Kommando-Zeile triggern kann. Es wird noch besser! Es gibt ein NuGet-Package, dass es uns erlaubt, den Vorgang sauber parametrisiert auszuführen. Also legen wir los!
Zunächst gehen wir wieder einmal in die Eigenschaften des SSDT-Projektes. Dieses Mal interessiert uns das Tab “Build”.
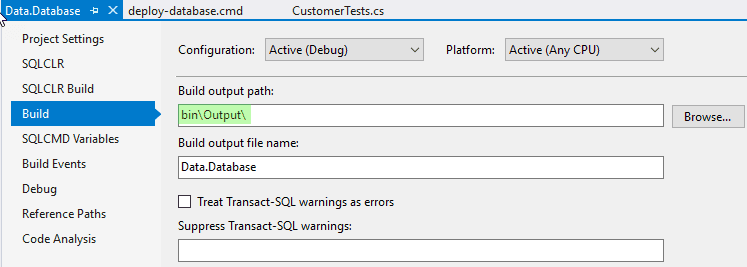
Ich setze den “Build Ouput Path” auf “bin\Output” anstatt des vorher eingestellten “bin\Debug”. Das gleiche wiederhole ich für jede vorhandene Build-Konfiguration. Sehen wir uns das an. Ein Rechtsklick auf das SSDT-Projekt und “Rebuild” erstellt das Projekt neu. Dann noch einmal Rechtsklick und “Open Folder In File Explorer” bringt uns zum Projekt-Ordner. Dort gehen wir in “bin” und dann “Output”. Das Ergebnis ist dies hier:
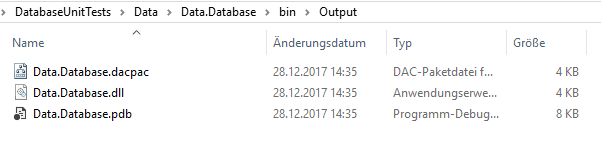
Die entscheidende Datei ist die Data.Database.dacpac. Ein DACPAC ist ein Deployment-Paket für eine SQL-Datenbank. Jeder SQL-Server ab Version 2012 kann damit umgehen und diese Datei installieren. Mann kann sie am ehesten mit dem Publish-ZIP-File von WebDeploy vergleichen. Dieses DACPAC werden wir nun verteilen.
Ich erstelle mir dazu auf der Ebene meiner Solution einen Ordner “.shared” und darin eine “deploy-database.cmd”. Beide Elemente füge ich dann im Visual Studio auch der Solution hinzu. Die cmd-Datei sieht wie folgt aus:
cd ..\packages
nuget.exe install Microsoft.Data.Tools.Msbuild -ExcludeVersion -Source https://api.nuget.org/v3/index.json
cd Microsoft.Data.Tools.Msbuild*\lib\net46
sqlpackage.exe /a:publish /Profile:..\..\..\..\Data\Data.Database\TestSystemWithSeeding.publish.xml /TargetDatabaseName:unittest /Sourcefile:..\..\..\..\Data\Data.Database\bin\Output\Data.Database.dacpacGehen wir es einmal Zeile für Zeile durch
- Wir gehen in den packages-Ordner der Solution.
- Wir nutzen
nuget.exe, um uns das Paket “Microsoft.Data.Tools.Msbuild” zu ziehen (Achtung! Ich gehe davon aus, dass Ihr eine Path-Variable auf nuget.exe habt.) - Wir gehen in den Ordner für das neu heruntergeladene Paket. Da wir die aktuelle Version nicht kennen, benutzen wir den
*-Trick, um in den Ordner zu gelangen. - Wir führen
sqlpackage.exeaus, die über das NuGet-Paket gekommen ist. Als Aktion verwenden wir “Publish”, als Profil unsere zuvor gespeicherte “*.publish.xml”-Datei und als Datei, die verteilt werden soll das DACPAC.
Man sollte beachten, dass ich mit dem Schalter “TargetDatabaseName” hier nun den im Profil eingestellten Namen “MyFirstAttempt” ignoriere und stattdessen eine Datenbank mit dem Namen “unittest” anlege. Das wird später noch bedeutsam.
Schritt 1 unternehme ich vor allem deshalb, damit das NuGet-Paket in den packages-Ordner kommt und Ordnung herrscht. Man kann einem SSDT-Projekt selbst leider keine NuGet-Referenzen mitgeben, weshalb ich das hier im Script erledige.
Das muss man trotzdem noch ein wenig erklären. Was macht sqlpackage.exe? Der Hintergrund ist der, dass das gesamte Database-Deployment von SSDT (wie auch das von Web-Projekten) letztlich auf MSBuild beruht. Die “*.publish.xml”-Datei ist eine Steuer-Datei für MSBuild und MSDeploy.
Bis zum Erscheinen des NuGet-Paketes “Microsoft.Data.Tools.Msbuild” musste man das Scripting für das Deployment noch aufwendig von Hand betreiben. sqlpackage.exe bringt nun Abhilfe. Die Dokumentation ist ziemlich ausführlich, auch wenn der Hinweis, dass der “Profile”-Schalter für die “*.publish.xml”-Dateien gedacht ist ruhig auftauchen dürfte.
Wie dem auch sei, das Skript sollte sauber durchlaufen und die Datenbank zuverlässig neu erstellen.
Unit-Tests erzeugen sich eine Datenbank
Wir haben unser Ziel noch nicht ganz erreicht. Es fehlen 2 Schritte:
- Jeder Unit-Test-Lauf muss letztlich das Skript triggern.
- Unit-Tests dürfen sich Datenbanken nicht gegenseitig “wegschnappen”.
Punkt 1 dieser Liste ist noch relativ leicht umzusetzen, der zweite erfordert etwas Trickserei.
Für den ersten Schritt füge ich meinem Unit-Test-Projekt eine neue Klasse TestHandler hinzu:
[TestClass]
public class TestHandler
{
#region methods
/// <summary>
/// Is called by the test runtime when the test environment loads.
/// </summary>
/// <param name="context">The test context.</param>
[AssemblyInitialize]
public static void AssemblyInit(TestContext context)
{
Trace.TraceInformation("Assembly initializing is starting.");
Context = context;
var file = GetScriptFileName();
Trace.TraceInformation($"Starting script {file}...");
if (file == null)
{
throw new FileNotFoundException("Could not locate database deploy script.");
}
var procInfo = new ProcessStartInfo(file.FullName)
{
WorkingDirectory = file.Directory.FullName,
WindowStyle = ProcessWindowStyle.Normal
};
var proc = Process.Start(procInfo);
proc?.WaitForExit();
}
/// <summary>
/// Searches for the database-project and retrieves its full project-filename if found.
/// </summary>
/// <returns>The filename or <c>null</c> if the file wasn't found.</returns>
private static FileInfo GetScriptFileName()
{
try
{
var dir = new FileInfo(Assembly.GetExecutingAssembly().Location).Directory;
if (dir == null)
{
return null;
}
while (dir.Parent != null && !dir.GetDirectories(".shared").Any())
{
dir = dir.Parent;
if (dir == null)
{
return null;
}
}
dir = dir.GetDirectories(".shared").First();
var fileInfo = dir.GetFiles(ConfigurationManager.AppSettings["DatabaseDeployScript"]).First();
return fileInfo;
}
catch (Exception ex)
{
return null;
}
}
#endregion
#region properties
/// <summary>
/// The context for the current test run.
/// </summary>
protected static TestContext Context { get; set; }
/// <summary>
/// Retrieves the database name used for tests on the current machine.
/// </summary>
protected static string TestDatabaseName => $"unittest";
#endregion
}Der Startpunkt ist hier die Methode AssemblyInit. Sie ist mit dem AssemblyInitializeAttribute dekoriert und muss daher statisch sein und einen Parameter vom Typ TestContext entgegen nehmen. Den merken wir uns in einer statischen Eigenschaft und versuchen dann, das vorher erstellte Script auf der Platte zu finden (darum sollte es z.B. Bestandteil der Solution sein). Es gibt wahrscheinlich elegantere Wege, das zu erledigen. Fühlt Euch frei!
Wichtig ist hier, dass dieser Code einen Konfigurations-Wert benötigt, den wir der App.config des Test-Projektes noch hinzufügen müssen. Ebenfalls an dieser Stelle müssen wir noch den “inital catalog” erneut anpassen und auf “unittest” stellen:
<connectionStrings>
<add name="UnitTestSampleEntities"
connectionString="metadata=res://*/SampleModel.csdl|res://*/SampleModel.ssdl|res://*/SampleModel.msl;provider=System.Data.SqlClient;provider connection string="data source=(LocalDb)\v11.0;initial catalog=unittest;integrated security=True;MultipleActiveResultSets=True;App=EntityFramework""
providerName="System.Data.EntityClient" />
</connectionStrings>
<appSettings>
<add key="DatabaseDeployScript" value="deploy-database.cmd" />
</appSettings>Das wird vor allem dann wichtig, wenn wir irgendwann einmal zwischen Test- und Prod-System unterscheiden müssen. Dann sollten wir die Scripts entsprechend aufteilen.
Wenn wir jetzt den Unit-Test erneut ausführen, erscheint ein Konsolen-Fenster und informiert uns über den Fortschritt in deploy-database.cmd. Danach verschwindet des Fenster und der Unit-Test sollte funktionieren.
Fast Fertig!
Variable Datenbank-Namen
Aus dem vorhergehenden Kapitel ist nun noch ein Problem übrig geblieben. Stellen wir uns vor, wir arbeiten zu zweit am selben Projekt. Es ist ein SQL Azure-Datenbankserver mit der DB “unittest” als Test-SQL konfiguriert (in *.publish.xml).
Entwickler A führt nun seine Unit-Tests aus und diese dauern - sagen wir - 5 Minuten. Eine Minute danach startet Entiwckler B ebenfalls seine Tests. Was wird geschehen? Ganz richtig: Entwickler A wird plötzlich einen Fehler erhalten, weil seinem Test-Run die Datenbank unter dem A… weggezogen wurde. Das ist also keine Option.
Ich habe länger über das Problem nachgedacht und entschieden, dass ich dafür sorgen möchte, dass die Datenbanknamen immer nach dem Muster “unittest-{MACHINENNAME}” erzeugt werden sollen. Das hat den Vorteil, dass auch ein Entwickler, der die Tests 2 mal mit dem gleichen Usernamen von unterschiedlichen Maschinen aus startet immer eine eindeutige Datenbank bekommt (wenn die Maschinen nicht gleich heißen :-)). Wer möchte, kann sich hier etwas anderes ausdenken.
Die Änderung ist zunächst trivial. Im deploy-database.cmd passen wir den sqlpackage.exe einfach an:
sqlpackage.exe /a:publish /Profile:..\..\..\..\Data\Data.Database\TestSystemWithSeeding.publish.xml /TargetDatabaseName:unittest-%COMPUTERNAME% /Sourcefile:..\..\..\..\Data\Data.Database\bin\Output\Data.Database.dacpacIch habe also einfach ”-%COMPUTERNAME%” an den TargetDatabaseName angehängt. Jetzt wisst Ihr auch, warum ich diesen Parameter überhaupt explizit im sqlpackage-Aufruf überschrieben habe.
Das klappt nun zwar bringt uns aber in andere Probleme. Jetzt wird nämlich zwar korrekt die Datenbank unter diesem Namen angelegt, aber meine App.config weiß ja davon noch nichts und dementsprechend bekomme ich keine Connection zur DB.
Hier wird es noch einmal knifflig. Zunächst fügen wir unserem Unit-Test-Projekt ein weiteres NuGet-Paket hinzu:
install-package MSBuild.Extension.Pack -ProjectName Tests.Data.CoreNun öffnen wir die Datei `Tests.Data.Core.csproj” in einem Editor und fügen unten folgende Elemente ein:
<PropertyGroup>
<BuildComputerName>$([System.String]::Copy('$(COMPUTERNAME)').ToLower())</BuildComputerName>
</PropertyGroup>
<ItemGroup>
<ConfigFile Include="bin/$(Configuration)/$(AssemblyName).dll.config" />
</ItemGroup>
<Target Name="AfterBuild">
<Message Text="Changing connection string in @(ConfigFile)." />
<MSBuild.ExtensionPack.FileSystem.File TaskAction="Replace" RegexPattern="initial catalog=*.?;" Replacement="initial catalog=unittest-$(BuildComputerName);" Files="@(ConfigFile)" />
</Target>Auch das muss ich wieder erläutern.
- In Zeile 2 wird eine Build-Variable mit dem Namen der aktuellen Maschine erstellt. Das bedeutet, dass wir im weiteren Verlauf über
$(BuildComputerName)diesen Namen überall verwenden können. - In Zeile 5 speichere ich mir den Pfad zur aktuellen
App.configunabhängig von der verwendeten Build-Configuration in der Variablen@(ConfigFile). - In Zeile 9 wird nun ein RegEx-Build-Task genutzt, den wir über das zuvor installierte NuGet-Paket
MSBuild.Extension.Packerhalten haben. Dieser Task sucht nach der Zeichenfolge “initial catalog=” gefolgt von beliebigen Zeichen und Zahlen und terminiert durch ein ”;“. Diesen ersetzt der Task dann durch “unittest-$(BuildComputerName)“.
Da das ganze im target AfterBuild durchgeführt wird (ein Standard-Task von MSBuild), ersetzen wir also eine String in der Ergebnisdatei “DatabaseUnitTest.Data.Core.dll.config” im entsprechenden bin-Unterordner.
Jetzt müssen wir noch Hand an die Klasse TestHandler anlegen. Erninnert Ihr Euch an die Property TestDatabaseName?. Sie muss nun angepasst werden:
protected static string TestDatabaseName => $"unittest-{Environment.MachineName.ToLower()}";Führt man den Unit-Test jetzt aus, sieht man im SQL Server Management Studio eine neue Datenbank mit dem entsprechenden Namen und alles läuft.
Weil wir verantwortungsbewusst sind…
Wir könnten jetzt aufhören, aber eine kleine Änderung macht uns und den DB-Admins das Leben angenehmer. Wie wäre es, wenn jeder Testlauf nach Abschluss die eigene Datenbank einfach wieder löschen würde? Kein Problem! Fügt folgende Methode der Klasse TestHandler hinzu:
/// <summary>
/// Is called when every test in this assembly is finished.
/// </summary>
[AssemblyCleanup]
public static void AssemblyCleanup()
{
Trace.TraceInformation("Assembly cleanup is starting.");
using (var ctx = new UnitTestSampleEntities())
{
try
{
ctx.Database.Delete();
Trace.TraceInformation("Database deleted.");
}
catch (Exception ex)
{
Trace.TraceError(ex.Message);
}
}
} Genau wie es das AssemblyInitializeAttribute gibt, existiert auch ein AssemblyCleanup. Es erforder ebenhalls eine statische Methode, die aber keinen Parameter erwarten darf. Sie wird nach Abschluss aller Unit-Tests einer Test-Assembly (Assembly = Visual Studio Projekt) ausgeführt. Wir nutzen hier einfach die Delete()-Methode von EF.
Probiert es aus und Ihr werdet die Datenbank im SQL Management Studio kurz sehen und dann verschwindet sie automatisch wieder.
Zusammenfassung
Das war mal wieder viel mehr Inhalt, als ich erwartet hatte und erwartet hatte ich bereits eine Menge! Mir ist aber wichtig, dass meine Leser das komplette Bild haben. Ich glaube, gerade für Leute, die sich mit MSBuild und MSDeploy nicht so auskennen, ist der Screen Cast ganz nützlich. Ich hoffe, ich konnte trotzdem gut aufzeigen, dass mit ein wenig Anpassung hier und da relativ coole Ergebnisse erzeugt werden können.